InfCode 在 SWE‑Bench Verified 上获世界最佳
词元无限团队
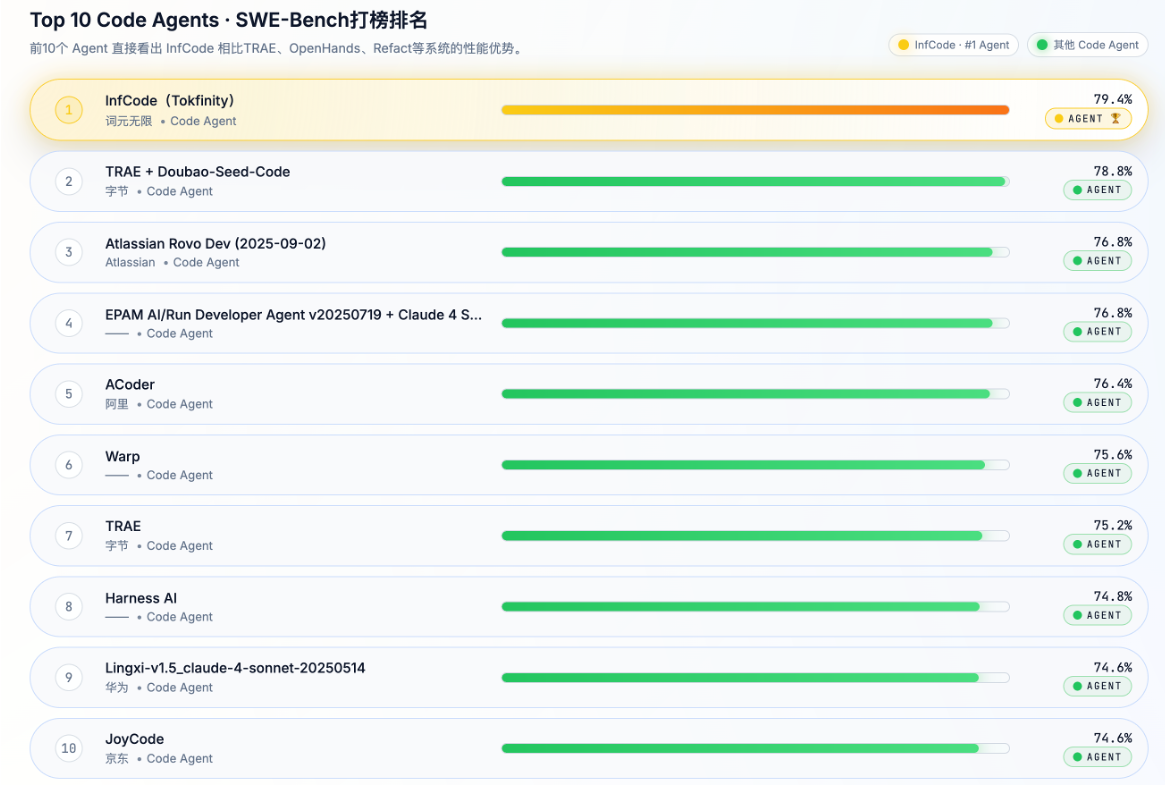
01 AI 编程进入智能体时代
人工智能正在改变软件开发范式。
传统的大模型只能生成代码片段,而新一代编码智能体(Coding Agent)强调自主性、全流程覆盖和工程实用性。它们不仅会写代码,还能分解任务、调用工具、运行测试、反复调试,甚至提交补丁。这些智能体在多个基准上接受评测,其中最具权威的是由普林斯顿大学等提出的 SWE‑Bench 基准,以及 OpenAI 于 2024 年发布的升级版 SWE‑Bench Verified。该基准来自真实 GitHub 项目,每个样本附带自然语言问题描述和完整的测试用例,要求智能体既要解决问题,又不能破坏其他功能。
SWE‑Bench Verified 仅包含 Python 项目,无法反映多语言生态的挑战。2025 年,字节跳动联合科研机构推出了 Multi‑SWE‑bench 数据集,覆盖 Java、TypeScript、JavaScript、Go、Rust、C 与 C++ 等七种语言,共计 1632 个经过人工验证的修复任务,由 68 名专家从 2456 个候选样本中精挑细选。
研究表明,C++ 项目通常需要一次修改 200 多行、涉及 7 个文件,这远难于 JavaScript 等高层语言;系统语言由于手动内存管理与复杂的编译体系使得 LLM 表现显著降低。对比官方报告,领先模型在 C++ 上的解决率往往不足 8%。
02 从学术走向工业:词元无限×北航——打造 InfCode 智能体
多语言基准显示,系统语言(C、C++、Rust)在内存管理、模板机制和复杂编译链方面的难度远高于 Python、Java 等高级语言。Multi‑SWE‑bench 中,C++ 问题往往涉及跨文件、大规模修改,部分任务需要改动 200 多行代码。
下表总结了 Multi‑SWE‑bench 各模型在 C++ 上的解决率:
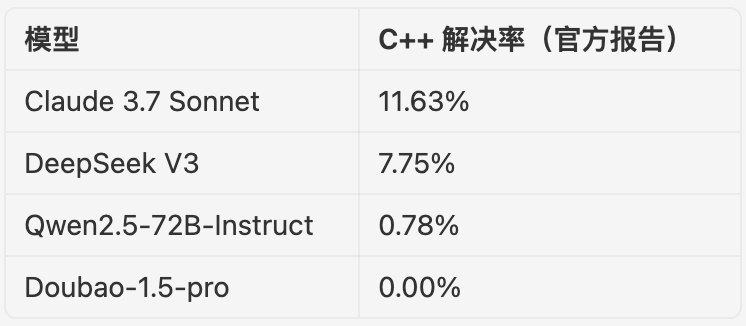
在此背景下,InfCode 在 C++ 子集上取得 25.58% 的 Pass@1 解决率,体现了语义定位与语法分析相结合的优势。它不仅能准确定位问题,更能在复杂语法和大型项目中生成正确补丁,这对工业界具有重要价值。下面,我们深入拆解 InfCode 的三大核心亮点。
超越 RAG:基于功能意图的复杂上下文定位
在真实的软件仓库中,真正困难的往往不是「写出补丁」,而是「先在海量代码中找到有问题的代码块」。
SWE‑Bench 的任务通常不提供堆栈追踪(StackTrace),智能体只能依靠自然语言描述(如搜索功能变慢)去推测问题发生的位置。传统基于向量相似度的 RAG(Retrieval-Augmented Generation)机制,往往只会检索到包含「search」关键词的注释或变量,这套机制在中小规模仓库上或许能够定位到问题位置,但在大型工程中容易停留在「字面相关」的片段附近 —— 例如命中带有 search 字样的工具函数、配置或包装层,而不是实际承载查询逻辑的实现位置(如 Manager::ExecuteQuery)。本质原因在于它主要感知的是局部向量相似度,而没有显式理解「代码承载的具体功能语义」及其「在系统中的逻辑归属」这类功能意图。
为突破这一瓶颈,InfCode 提出了「代码意图分析(Code Intent Analysis)」机制。
该机制让智能体能够超越字面匹配,理解自然语言背后的「功能意图」,并将其智能映射到项目中的具体实现单元(函数或类)。这一过程融合了语义推理与架构理解,使模型能在无堆栈信息的条件下仍然精准地锁定问题上下文。
研究表明,在多语言基准(如 Multi‑SWE‑bench)中,传统 LLM 往往无法正确识别文件或函数位置(尤其在 C++、Rust 等系统级语言中)。InfCode 的语义意图映射结合 AST 层级分析,有效提升了跨语言、跨模块的定位成功率,让智能体在复杂工程中具备了「理解全局意图、直达根因代码」的能力。
增强工具:超越 Grep 的基于 AST 的结构化检索
找到问题的代码只是第一步,如何精准定位并修改它才是工程修复的关键。传统的文本搜索工具(如 grep)在 C++ 等复杂语言中存在天然缺陷 —— 同一标识符可能同时是类名、成员函数或变量,导致结果噪声极高。字节跳动团队在 Multi‑SWE‑bench 的研究中指出,C++ 与 Rust 项目通常涉及跨文件、大规模修改,这使得「语义感知检索」成为智能体系统的必需能力。
InfCode 自研了基于抽象语法树(AST)的结构化检索引擎。它通过 Tree‑Sitter 构建完整的语法树,为智能体提供 FindClass、FindFunction 等语法层 API。例如:
• FindClass (Search):只返回名为 Search 的类定义,自动忽略同名函数或变量;
• FindFunctions (MyClass::search):仅匹配特定类的成员函数。
这种语法感知搜索(Syntax‑Aware Search)的理念与开源工具 ast‑grep 不谋而合 —— 它被称为「语法层的 grep/sed」,能通过 AST 模式快速定位与重写代码。借助这种结构化检索,InfCode 的智能体不再「盲搜」,而是真正「理解」代码的层次结构,在复杂工程中实现更高精度的 bug 定位与安全修复。
多智能体生成:基于对抗式的代码补丁与测试补丁双智能体生成
修复能力的核心不在于「一次命中」,而在于反复试错、持续进化。
传统代码修复智能体多采用单智能体架构,无论是先生成测试补丁再生成修复代码,亦或是先生成修复代码再回测验证,这种单向的修复模式往往容易陷入「过拟合当前 Issue」的信息茧房。
InfCode 首创对抗式双智能体架构:
• 代码补丁生成器(CodePatch Generator)负责修改代码通过当前测试集;
• 测试补丁生成器(Test Patch Generator)负责生成更强的测试用例,捕捉遗漏的边界场景。
二者在一个闭环中交替迭代:
当代码补丁通过测试后,测试补丁生成器会自动分析潜在漏洞并扩展测试覆盖度;随后代码补丁生成器必须进一步修复代码以应对新的挑战。
这种「越测越强、越修越稳」的对抗式工作流,让补丁在鲁棒性与完备性上持续演化,最终达到可直接集成于生产仓库的工程级质量。
这一设计契合了当前代码智能体研究的发展趋势:高水平智能体不仅要会生成,更要会验证与自我改进。
正如近期研究结果,单轮生成模式已难以支撑复杂工程任务,迭代‑验证‑优化的闭环结构将成为下一代 Coding Agent 的核心范式。更多关于 InfCode 的技术细节可以参考团队发表于 arXiv 的技术报告: 报告一 https://arxiv.org/abs/2511.16004 报告二 https://arxiv.org/abs/2511.16005
03 工程化细节:生成与筛选范式
InfCode 的修复流程分为两阶段:生成(Generate)与筛选(Select)。
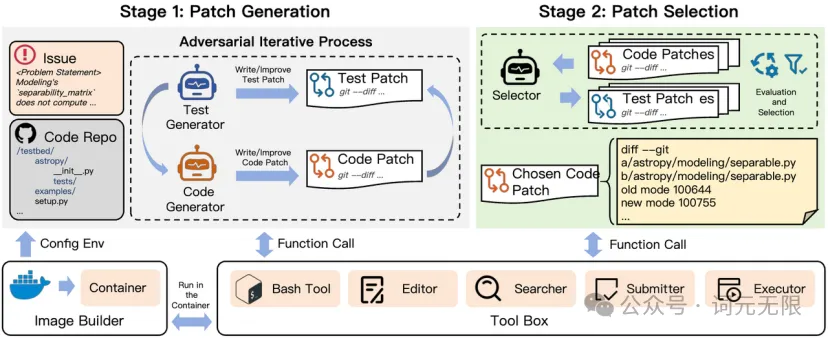
在生成阶段,系统并行启动多个独立容器,每个容器运行一条修复链路,允许模型查看代码库、运行测试、分析错误,并迭代生成候选补丁。最多经历五轮迭代,产生多样化的补丁组合。
筛选阶段,系统在真实构建和测试环境中重放每个补丁,除了验证测试通过与否,还考虑行为一致性、稳定性和副作用。最终选出的补丁不仅「跑通测试」,还具有更强的工程完整性与可维护性。这种广泛探索 + 精准筛选的策略使 InfCode 能产出质量更高的修复补丁,而非过拟合或脆弱的修改方案。
04 团队介绍
复杂关键软件环境全国重点实验室(原软件开发环境国家重点实验室)依托北京航空航天大学建设,是我国信息领域最早的重点实验室之一。实验室定位于复杂关键软件环境的应用基础研究,加强现代工程和技术科学研究,聚焦开发效率、可信保障和持续演化,重点研制开发运行一体化智能软件环境,强化复杂关键软件技术链、产业链和生态链的支撑能力。
词元无限核心团队不仅拥有顶尖的技术实力,更难得的是将技术前瞻、产品化能力与商业化思维三者融为一体,这在当下竞争激烈的 AI Coding Agent 赛道中,构成难以复制的全链路优势。